# Provider can be: ollama, google, openai, anthropic, groq, or openrouter
AI_CHAT_PROVIDER=ollama
AI_EMBEDDING_PROVIDER=ollama
AI_DESCRIPTION_PROVIDER=ollama
AI_AGENT_BUDDY_PROVIDER=ollama
# API Keys for each functionality (only needed if using that provider)
# The same key will be used for the selected provider in each category
AI_CHAT_API_KEY=None
AI_EMBEDDING_API_KEY=None
AI_DESCRIPTION_API_KEY=None
AI_AGENT_BUDDY_API_KEY=None
# Azure OpenAI
# when using openai as a provider and you want to use Azure OpenAI, set these variables
# the endpoint should be in the format: https://.openai.azure.com/
AZURE_OPENAI_ENDPOINT=None
# The API version to access your OpenAI resource. E.g. 2024-07-01-preview
OPENAI_API_VERSION=None
# Model names for each provider
# For ollama: llama2, codellama, mistral, etc. (embedding)
# For OpenAI: gpt-4, gpt-3.5-turbo, text-embedding-ada-002 (embedding)
# For OpenRouter: anthropic/claude-3-opus, openai/gpt-4-turbo, google/gemini-pro, etc.
# For Google: gemini-pro, gemini-pro-vision
# For Anthropic: claude-3-5-sonnet-latest, claude-3-opus-20240229, claude-3-haiku-20240307
# For Groq: llama3-8b-8192, llama3-70b-8192, mixtral-8x7b-32768
CHAT_MODEL=llama2
EMBEDDING_MODEL=all-minilm:33m
DESCRIPTION_MODEL=llama2
AI_AGENT_BUDDY_MODEL=llama3.2
# Optional: Site information for OpenRouter rankings
SITE_URL=http://localhost:3000
SITE_NAME=Local Development
# Performance settings (LOW, MEDIUM, MAX)
# LOW: Minimal resource usage, suitable for low-end systems
# MEDIUM: Balanced resource usage, suitable for most systems
# MAX: Maximum resource usage, suitable for high-end systems
PERFORMANCE_MODE=MEDIUM
# Maximum number of threads to use (will be calculated automatically if not set)
MAX_THREADS=16
# Cache size for embedding queries (higher values use more memory but improve performance)
EMBEDDING_CACHE_SIZE=1000
# Similarity threshold for embedding search (lower values return more results but may be less relevant)
EMBEDDING_SIMILARITY_THRESHOLD=0.05
# API Rate Limiting Settings
# Delay in milliseconds between embedding API calls to prevent rate limiting
# Recommended: 100ms for Google, 0ms for OpenAI/Ollama (set to 0 to disable)
EMBEDDING_API_DELAY_MS=100
# Delay in milliseconds between description generation API calls to prevent rate limiting
# Recommended: 100ms for Google, 0ms for OpenAI/Ollama (set to 0 to disable)
DESCRIPTION_API_DELAY_MS=100
# UI Settings
# Enable/disable markdown rendering (TRUE/FALSE)
ENABLE_MARKDOWN_RENDERING=TRUE
# Show thinking blocks in AI responses (TRUE/FALSE)
SHOW_THINKING_BLOCKS=FALSE
# Enable streaming mode for AI responses (TRUE/FALSE) # Tends to be slower for some reason # Broken for openrouter TODO: Fix this at some point !
ENABLE_STREAMING_MODE=FALSE
# Enable chat logging to save conversations (TRUE/FALSE)
CHAT_LOGS=FALSE
# Enable memory for AI conversations (TRUE/FALSE)
MEMORY_ENABLED=TRUE
# Maximum number of memory items to store
MAX_MEMORY_ITEMS=10
# Execute commands without confirmation (TRUE/FALSE)
# When FALSE, the user will be prompted to confirm before executing any command
# When TRUE, commands will execute automatically without confirmation
COMMANDS_YOLO=FALSE
# HTTP API Server Settings
# Allow connections from any IP address (TRUE/FALSE)
# When FALSE, the server only accepts connections from localhost (127.0.0.1)
# When TRUE, the server accepts connections from any IP address (0.0.0.0)
# WARNING: Setting this to TRUE may expose your API to the internet
HTTP_ALLOW_ALL_ORIGINS=FALSE
# MCP Server Settings
# URL of the HTTP API server
MCP_API_URL=http://localhost:8000
# Port to run the HTTP API server on
MCP_HTTP_PORT=8000
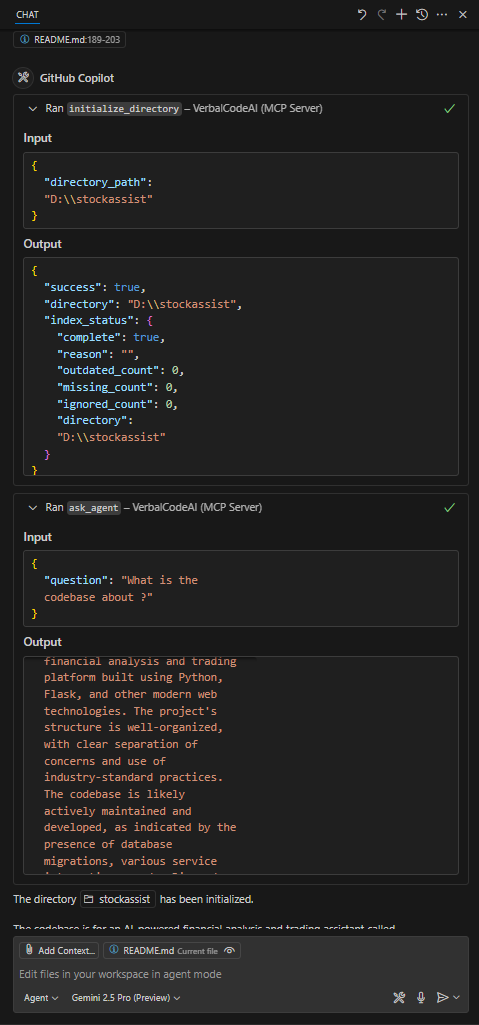
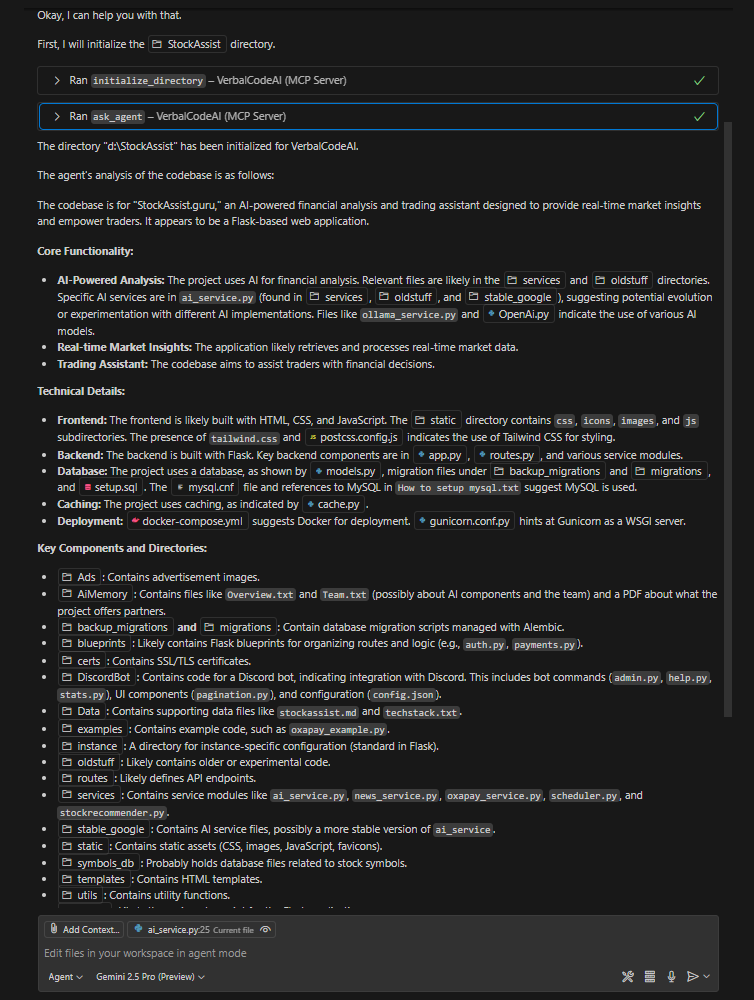
Recommended Ollama Setup
For the best local experience without any API costs, the developer recommends using these Ollama models:
- Chat/Description:
gemma3 - Google's Gemma 3 model provides excellent code understanding and generation
- Embeddings:
all-minilm - Efficient and accurate embeddings for code search and retrieval
# Install the recommended models
ollama pull gemma3
ollama pull all-minilm
# Configure in .env
AI_CHAT_PROVIDER=ollama
AI_EMBEDDING_PROVIDER=ollama
AI_DESCRIPTION_PROVIDER=ollama
CHAT_MODEL=gemma3
EMBEDDING_MODEL=all-minilm:33m
DESCRIPTION_MODEL=gemma3
Anthropic Claude Models
Anthropic's Claude models are particularly strong at understanding and generating code. Available models include:
- claude-3-5-sonnet-latest: Latest version of Claude 3.5 Sonnet, excellent balance of performance and speed
- claude-3-opus-20240229: Most powerful Claude model with advanced reasoning capabilities
- claude-3-haiku-20240307: Fastest and most cost-effective Claude model
Note: Anthropic does not provide embedding capabilities, so you'll need to use a different provider for embeddings.
Groq Models
Groq provides ultra-fast inference for popular open-source models. Available models include:
- llama3-8b-8192: Smaller Llama 3 model with 8B parameters, good balance of performance and speed
- llama3-70b-8192: Larger Llama 3 model with 70B parameters, excellent reasoning capabilities
- mixtral-8x7b-32768: Mixtral model with 8x7B parameters and 32k context window
Note: Groq does not provide embedding capabilities, so you'll need to use a different provider for embeddings.